UC San Diego's TritonGPT Chatbot Upgraded to Llama 3
[Update: August 2024]
The University of California San Diego (UC San Diego) TritonGPT chatbot was upgraded to Llama 3 along with the institution's vLLM, its CIO announced.
Currently, 17,105 faculty and staff have access to TritonGPT. By the end of May, it will add another 19,502 people for 36,607 with access.
As a platform, TritonGPT uses open-source software and runs on-premise, at low cost, in partnership with the San Diego Supercomputer Center.
TritonGPT, a suite of AI Assistants, handles university-specific questions, creates tailored content, and summarizes documents. It helps students navigate UC San Diego's policies, procedures, and campus life.
"It's like having a personal assistant who knows a lot about UC San Diego," said the university.
Tasks that can be accomplished are, according to the university:
Ask UC San Diego Related Questions: Pose questions like "What is the policy on employee travel reimbursement?" or "What are some good restaurants on campus?" TritonGPT will provide detailed and relevant information.
Content Generation: Need help with content creation? Try commands like "Generate an outline for a presentation slide deck based on <insert topic>" or "Produce an email to thank my employees for <insert what you are thankful for>."
Document Summarization: Copy and paste documents or articles related to UC San Diego, then ask TritonGPT to summarize the content. It's a time-saving feature for extracting key information.
Content Editing: Utilize TritonGPT for editing and refining content related to UC San Diego. It's a valuable tool for polishing emails, reports, or any written material.
Seek feedback and suggestions: TritonGPT can provide feedback and suggestions to help you improve your work processes and procedures. You can ask questions like "What are some ways I can improve my communication skills in the workplace?" or "Are there any suggestions for streamlining our team's workflow?"
Ask for Recommendations: Seeking recommendations for UC San Diego events, study spots, or local hangouts? TritonGPT has you covered.
TritonGPT consists of the following AI Assistants:
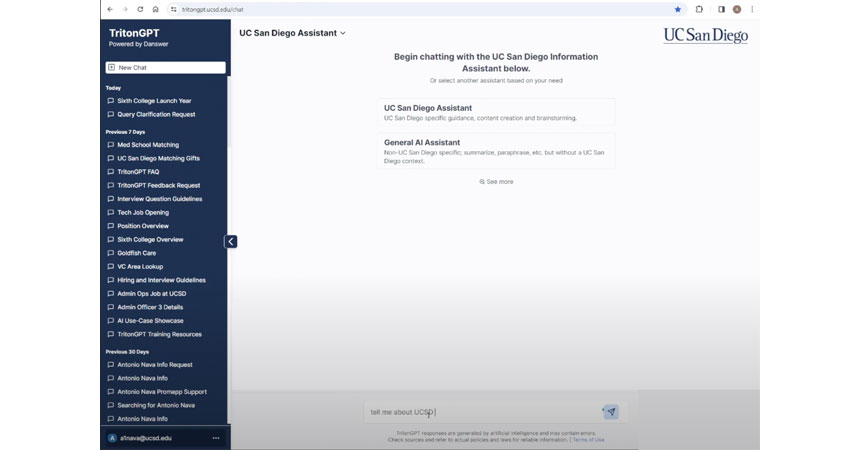
UC San Diego Assistant: UC San Diego-related policy, process, and help documentation is spread out over various websites. The UC San Diego Assistant brings it all together by answering your questions directly. It is also great for incorporating UC San Diego's context in generating new content and brainstorming ideas. Always reference the sources cited when relying upon their answers.
Job Description Helper: TritonGPT includes a Job Description Helper that will streamline the job description creation process for hiring managers. Leveraging over 1,300 career tracks job standard templates, it uses a predefined flow that engages hiring managers in a dialogue, capturing the job's specific requirements. The AI then crafts language that not only complies with established job card standards but also accurately reflects the unique characteristics of the position. This feature reduces the time and effort involved in drafting job descriptions, ensuring they are both precise and tailored to the individual needs of the role.
General AI Assistant: This tool expands beyond UC San Diego's scope, accommodating larger information exchanges. It interacts with a Large Language Model for tasks like document summarization, idea generation, and creating various content such as emails and reports.
Fund Manager Coach: Recognizing the crucial role of Fund Managers in overseeing grants and managing departmental finances, this assistant will enhance understanding of UC San Diego's financial policies and procedures. Fund Manager Coach is trained in the documentation for developing research proposal budgets, advising faculty on contract and grant guidelines, reviewing and approving financial transactions, managing payroll, and ensuring that applicable guidelines are being followed during contract and grant spending.
TritonGPT's UC San Diego has been trained on extensive public-facing university information, such as:
Academic Personnel website
Admissions website
Blink
Business Analytics Hub
Calendar of Events
Career Center
Chancellor website
The Commons
Course Catalog
Educational Technology
Foundation
Housing and Dining
Policies (UC San Diego and UCOP)
ServiceNow Knowledge Base content (public facing)
Strategic Plan
Student Financial Solutions
Transportation
TritonLink (students.ucsd.edu)
UC Path website
UC San Diego Brand
University Centers
University Communications
UC San Diego Today
UC San Diego also has partnered with a UC San Diego and a Y Combinator-funded startup, DanswerAI, to handle the TritonGPT user interface and the under-the-hood RAG management.
Brett Pollak is leading this initiative for the university.
.
[Disclosure: IBL.ai is a partner provider of UC San Diego]