Bloomberg Introduces a 50-Billion Parameter LLM Built For Finance
April 7, 2023

IBL News | New York
Bloomberg released this week a research paper introducing BloombergGPT, a new large-language (LLM) AI model with 50 billion parameter built from scratch for finance.
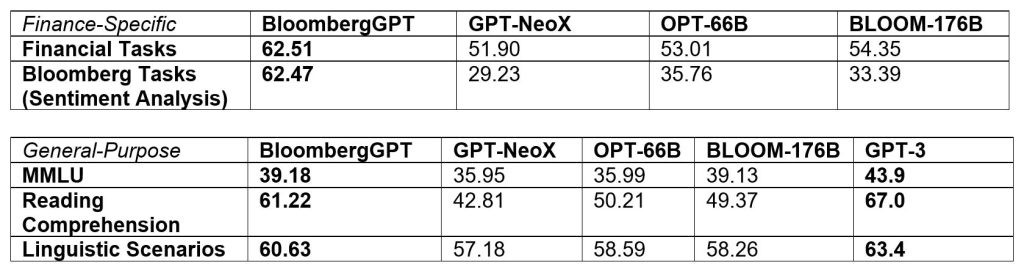
The company said that BloombergGPT, that has been specifically trained on a wide range of financial data, outperforms similarly-sized models by significant margins (as shown in the table below).
“It represents the first step in the development and application of this new technology for the financial industry,” said the company.
“This model will assist Bloomberg in improving existing financial NLP tasks, such as sentiment analysis, named entity recognition, news classification, and question answering, among others. Furthermore, BloombergGPT will unlock new opportunities for marshalling the vast quantities of data available on the Bloomberg Terminal.”
Bloomberg researchers pioneered a mixed approach that combines both finance data with general-purpose datasets to train a model that achieves best-in-class results on financial benchmarks, while also maintaining competitive performance on general-purpose LLM benchmarks.
Bloomberg’s data analysts collected financial language documents over the span of forty years, pulled from this extensive archive to create a comprehensive 363 billion token dataset consisting of English financial documents.
This data was augmented with a 345 billion token public dataset to create a large training corpus with over 700 billion tokens. Using a portion of this training corpus, the team trained a 50-billion parameter decoder-only causal language model.