An AI Application Allows to Ask Questions and Gain Insights About Documents
January 29, 2023
IBL News | New York
Businesses around large language models (LLMs) and ChatGPT continue popping up.
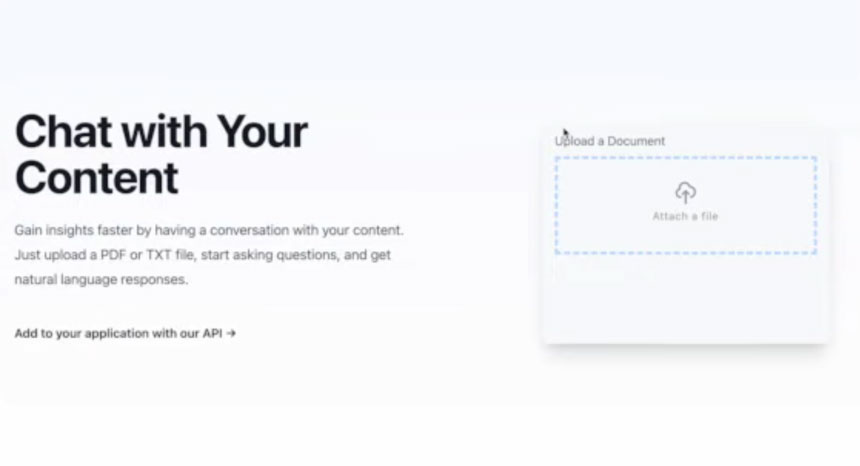
One of the latest is Usemeru.com, which allows people to ask questions about Documents, HTML Files, and JSON files in natural language. Large volumes of text can include recruiting call transcripts, request tickets from customers, and medical records.
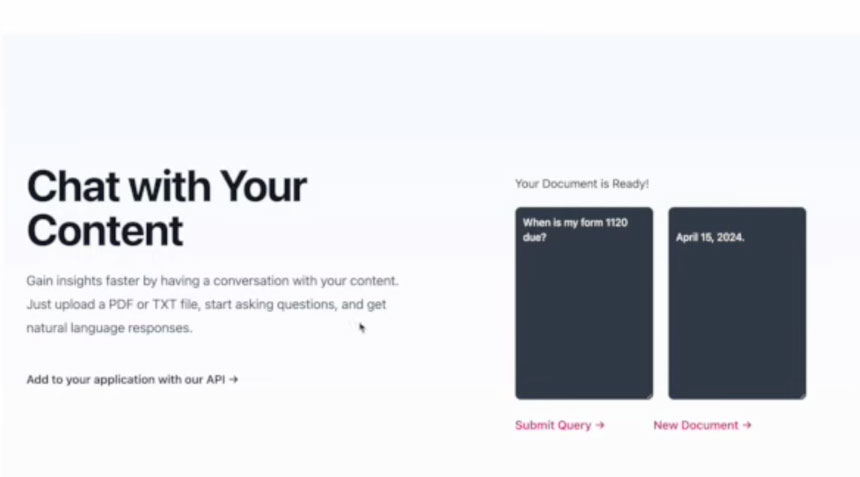
Users upload and index those documents and files and ask questions about the document. The app parses input and delivers natural language responses.
Essentially, when a client submits a document to Usermeru’s API, the system indexes the document and stores the index on the company servers. Clients can then query the index via an LLM, such as GPT-3, and obtain a response.
This approach is more robust than passing the document as a part of the prompt.
In addition, because the user is querying the index, he/she doesn’t waste tokens as prompts, and can therefore build much larger and more complex queries. Documents larger than 4096 tokens can also be queried effectively.
Usermeru.com also allows you to embed Stable Diffusion image generation into your applications with low latency, variable sizing, and automatic resolution upscaling.
The application is available as an API for dense data retrieval at a starting price of $2.75 per concept.
People in finance/investing, law, humanities/social science research might find this useful in order to search for documents.