
 En Español
En Español


















IBL News | New York
Training data provider Scale AI Inc., which serves OpenAI and Nvidia, published its LLM leaderboard ranking AI models’ performance, rating their capabilities in common use cases, such as generative AI coding, instruction following, math, and multilingualism.
The AI training company didn’t divulge the nature of the prompts it used to evaluate LLMs.
OpenAI’s GPT models rank first in three of the four initial domains, with Anthropic’s Claude 3 Opus grabbing first place in the fourth category. Google LLC’s Gemini models rank joint-first with the GPT models in a few domains.
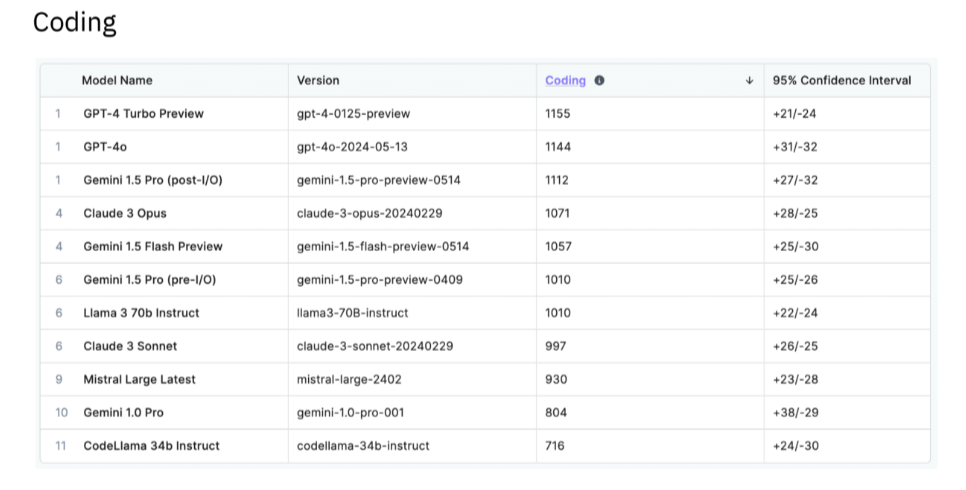
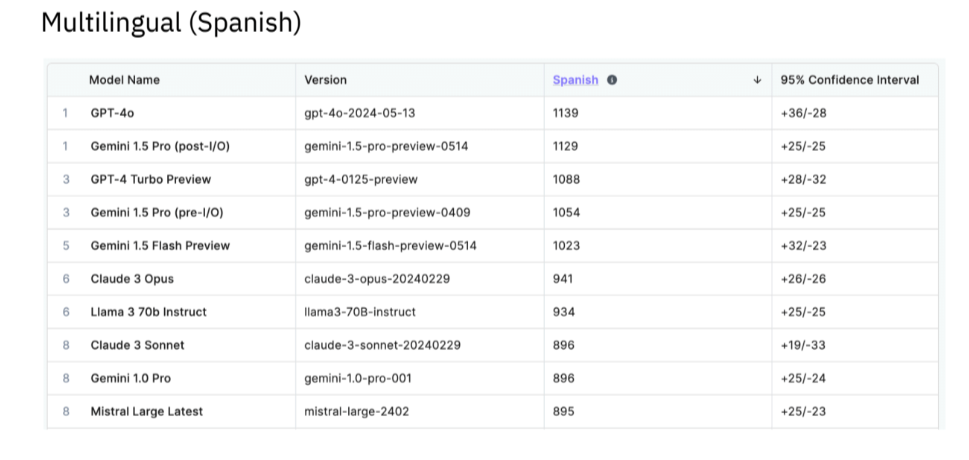
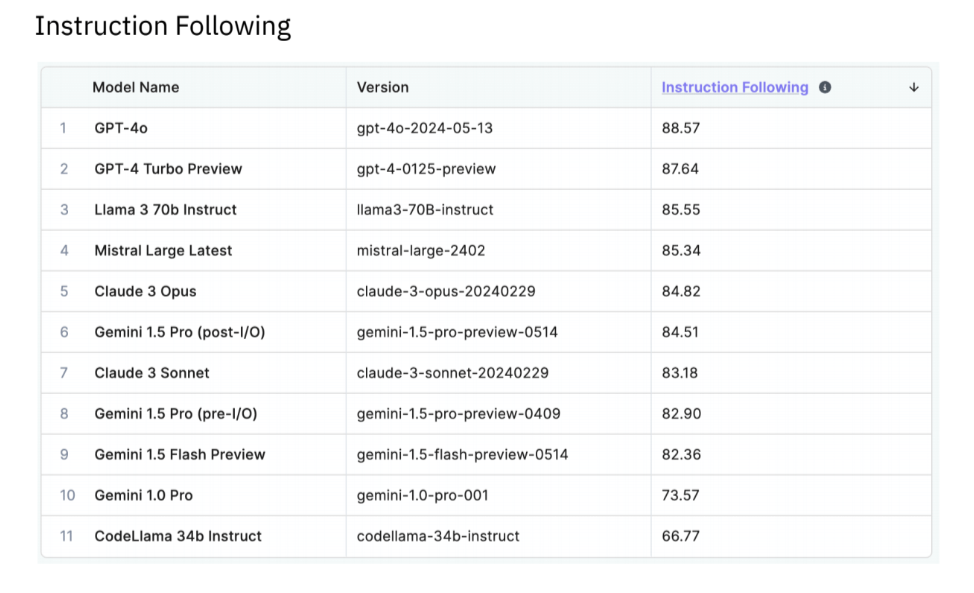
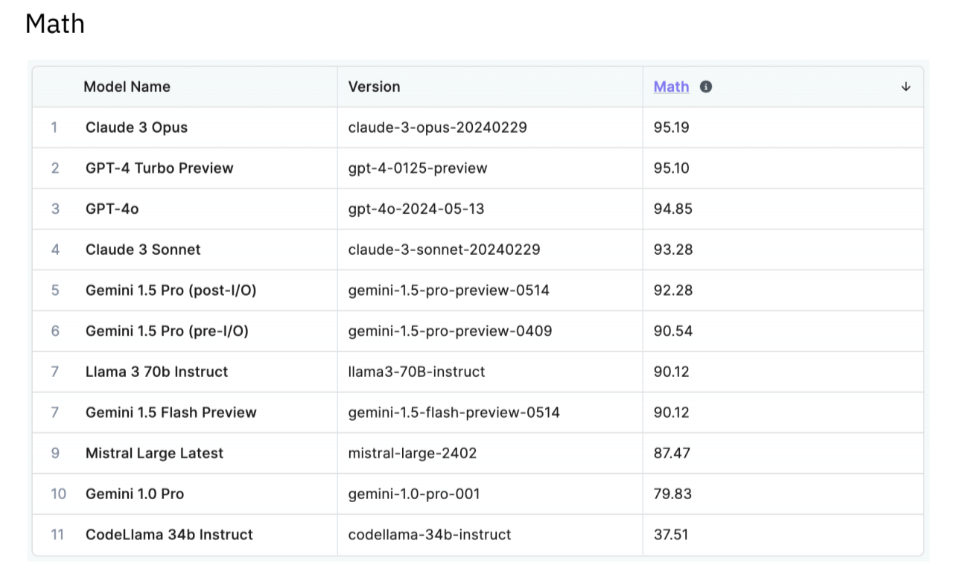
Many high-profile LLMs have been left out of the evaluations. For instance, AI21 Labs Inc.’s Jurassic and Jamba, Cohere Inc.’s Aya and Command LLMs, and xAI’s Grok are notably absent from these assessments.

