OpenAI's o1 Correctly Solved 83.3% of the Problems, While GPT-4o Only 13.4%
September 14, 2024
IBL News | New York
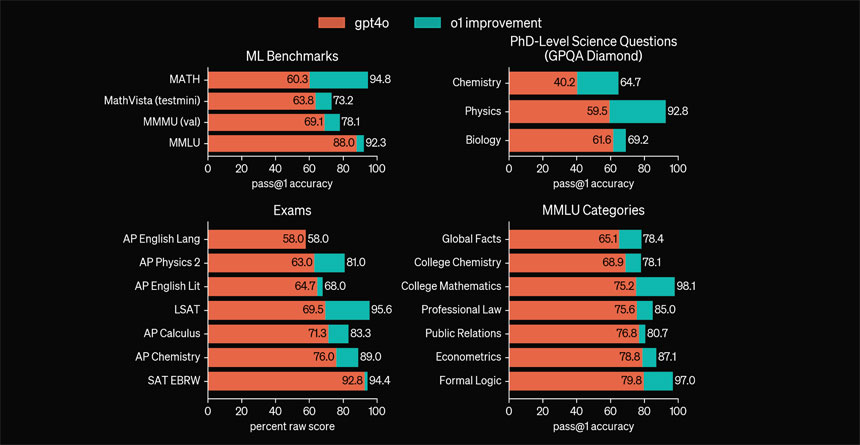
The new OpenAI’s o1 reasoning model —released on Thursday— scored 83% in a qualifying exam for the International Mathematics Olympiad (IMO), while GPT-4o correctly solved only 13% of problems.
Also, the coding abilities were evaluated in contests, and as indicated in an OpenAI research post, they reached the 89th percentile on competitive programming questions (Codeforces) competitions.
Trained with reinforcement learning to perform complex reasoning, this new LLM that excels in math and coding thinks before it answers—it can produce a long internal chain of thought before responding to the user.
According to OpenAI, it performs similarly to PhD students on challenging benchmark tasks in physics, chemistry, and biology.
“Our large-scale reinforcement learning algorithm teaches the model to think productively using its chain of thought in a highly data-efficient training process. We have found that o1’s performance consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute). The constraints on scaling this approach differ substantially from those of LLM pretraining, and we are continuing to investigate them,” said the company.
o1 is rate-limited; weekly limits are currently 30 messages for o1-preview and 50 for o1-mini.
An additional downside is its high, expensive price. In the API, o1-preview is $15 per 1 million input tokens and $60 per 1 million output tokens. That’s 3x the cost versus GPT-4o for input and 4x for output. (1 million tokens is equivalent to around 750,000 words.)
OpenAI says it plans to offer o1-mini access to all free users of ChatGPT but hasn’t set a release date. We’ll hold the company to that date.
Discover more
IBL News is funded by the New York-based, family-owned company ibl.ai. Our stories adhere to the highest ethical standards in journalism and are available to news syndication agencies.







