Meta Releases Llama 3, Two Models with 8 Billion and 70 Billion Parameters
April 19, 2024

IBL News | New York
Meta released this week Llama 3, with two models: Llama 3 8B, which contains 8 billion parameters, and Llama 3 70B, with 70 billion parameters. (The higher-parameter-count models are more capable than lower-parameter-count models.)
Llama 3 models are now available for download and experience at meta.ai. They will soon be hosted in managed form across a wide range of cloud platforms, including AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM’s WatsonX, Microsoft Azure, Nvidia’s NIM, and Snowflake. In the future, versions of the models optimized for hardware from AMD, AWS, Dell, Intel, Nvidia, and Qualcomm will also be made available.
Llama 3 models power Meta’s Meta AI assistant on Facebook, Instagram, WhatsApp, Messenger, and the web.
“Our goal in the near future is to make Llama 3 multilingual and multimodal, have longer context, and continue to improve overall performance across core [large language model] capabilities such as reasoning and coding,” Meta wrote in a blog post.

The company said that these two 8B and 70B models, trained on two custom-built 24,000 GPU clusters, are among the best-performing generative AI models available today. To support this claim, Meta pointed to the scores on popular AI benchmarks like MMLU (which attempts to measure knowledge), ARC (which attempts to measure skill acquisition), and DROP (which tests a model’s reasoning over chunks of text).
Llama 3 8B bests other open models such as Mistral’s Mistral 7B and Google’s Gemma 7B, both of which contain 7 billion parameters, on at least nine benchmarks: MMLU, ARC, DROP, GPQA (a set of biology-, physics- and chemistry-related questions), HumanEval (a code generation test), GSM-8K (math word problems), MATH (another mathematics benchmark), AGIEval (a problem-solving test set) and BIG-Bench Hard (a commonsense reasoning evaluation).
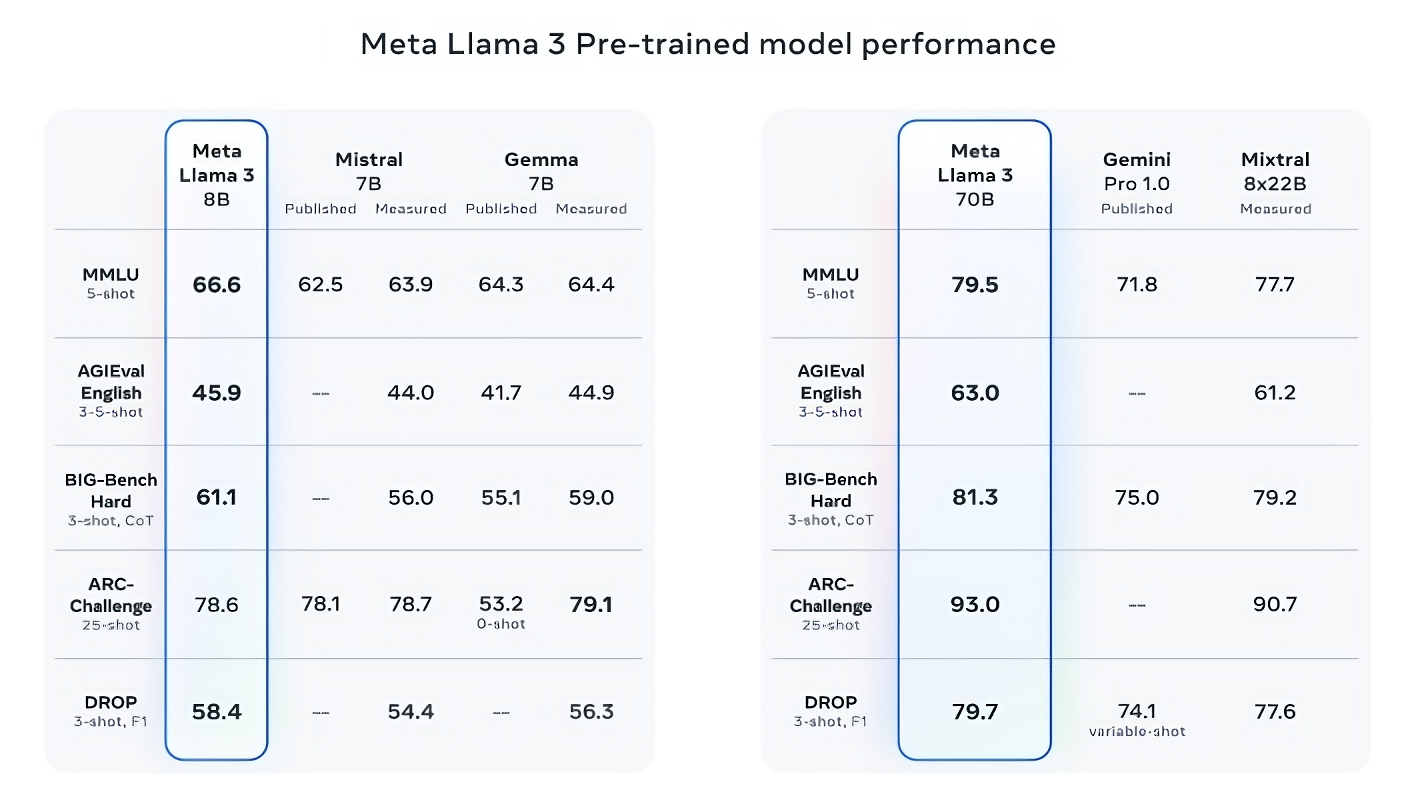
Llama 3 70B beats Gemini 1.5 Pro on MMLU, HumanEval, and GSM-8K, and — while it doesn’t rival Anthropic’s most performant model, Claude 3 Opus — Llama 3 70B scores better than the second-weakest model in the Claude 3 series, Claude 3 Sonnet, on five benchmarks (MMLU, GPQA, HumanEval, GSM-8K and MATH).
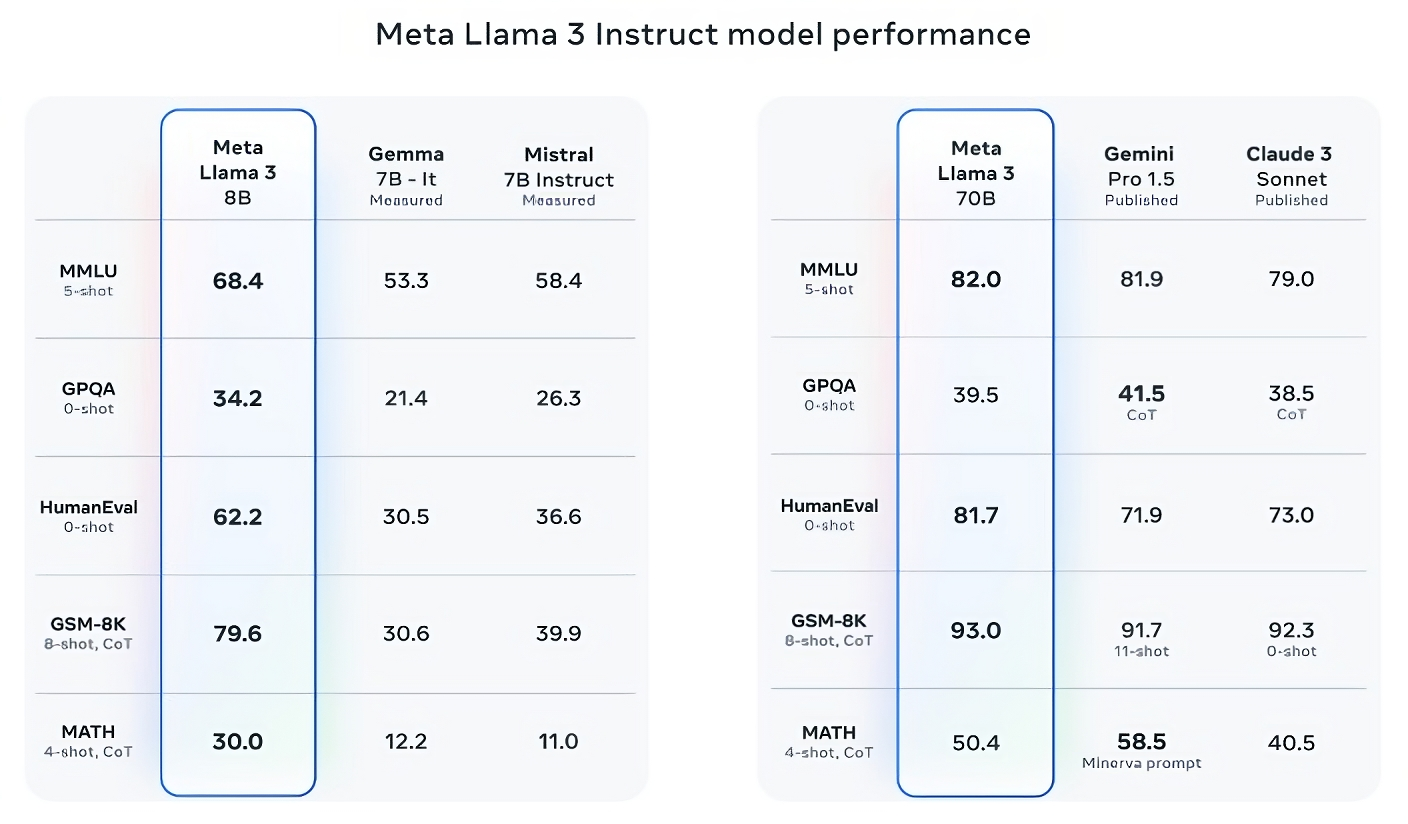
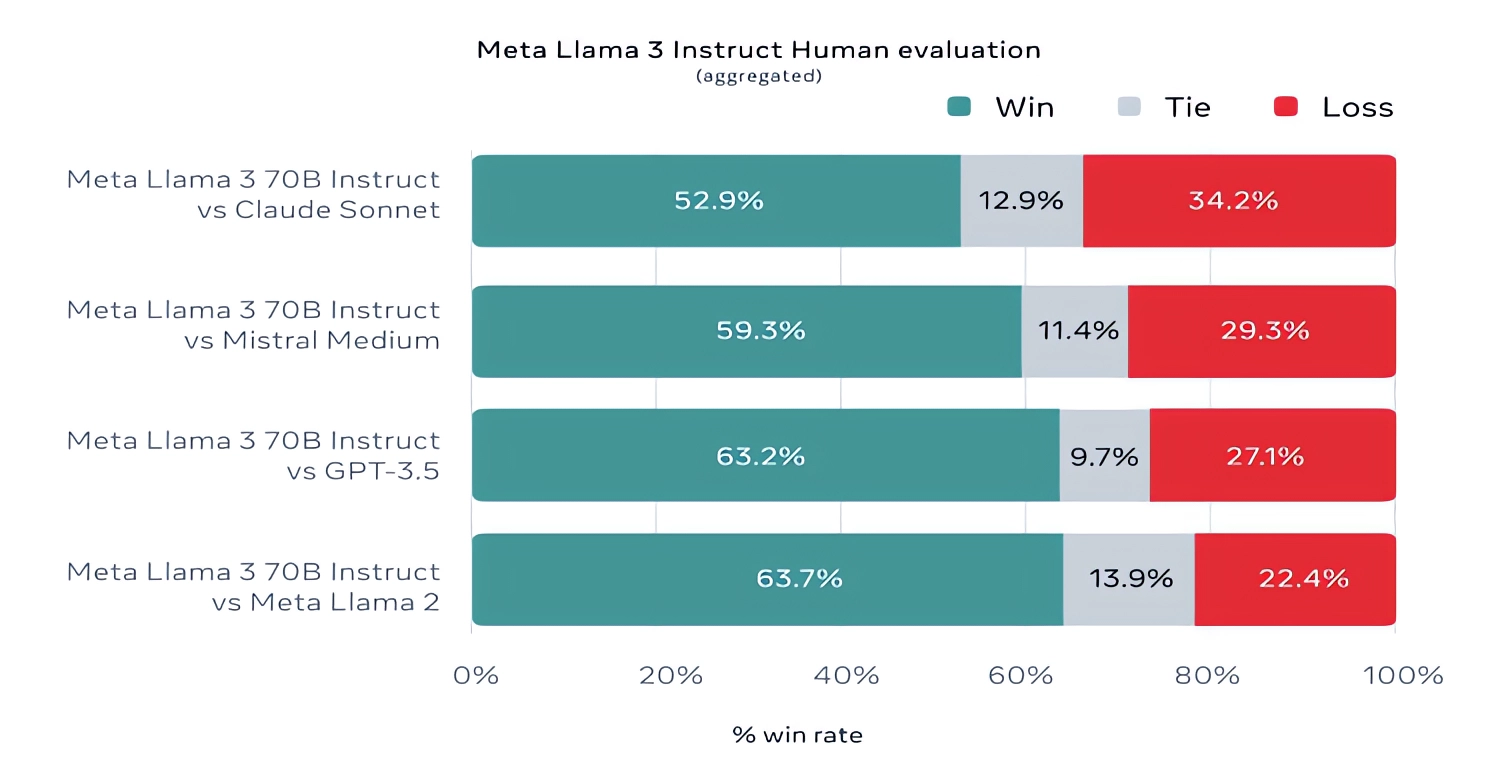
Meta also developed its own test set covering use cases ranging from coding and creative writing to reasoning to summarization. Llama 3 70B came out on top against Mistral’s Mistral Medium model, OpenAI’s GPT-3.5, and Claude Sonnet.
.
Meta Llama 3 is very good, especially for such a small model. We can put in a multi-page prompt like our negotiation simulator (https://t.co/j6BcWh4zFb) & it is able to follow the complexity reasonably well. It doesn’t have the “smarts” of GPT-4 class, but impressive nonetheless. pic.twitter.com/qMaRtwogqA
— Ethan Mollick (@emollick) April 18, 2024
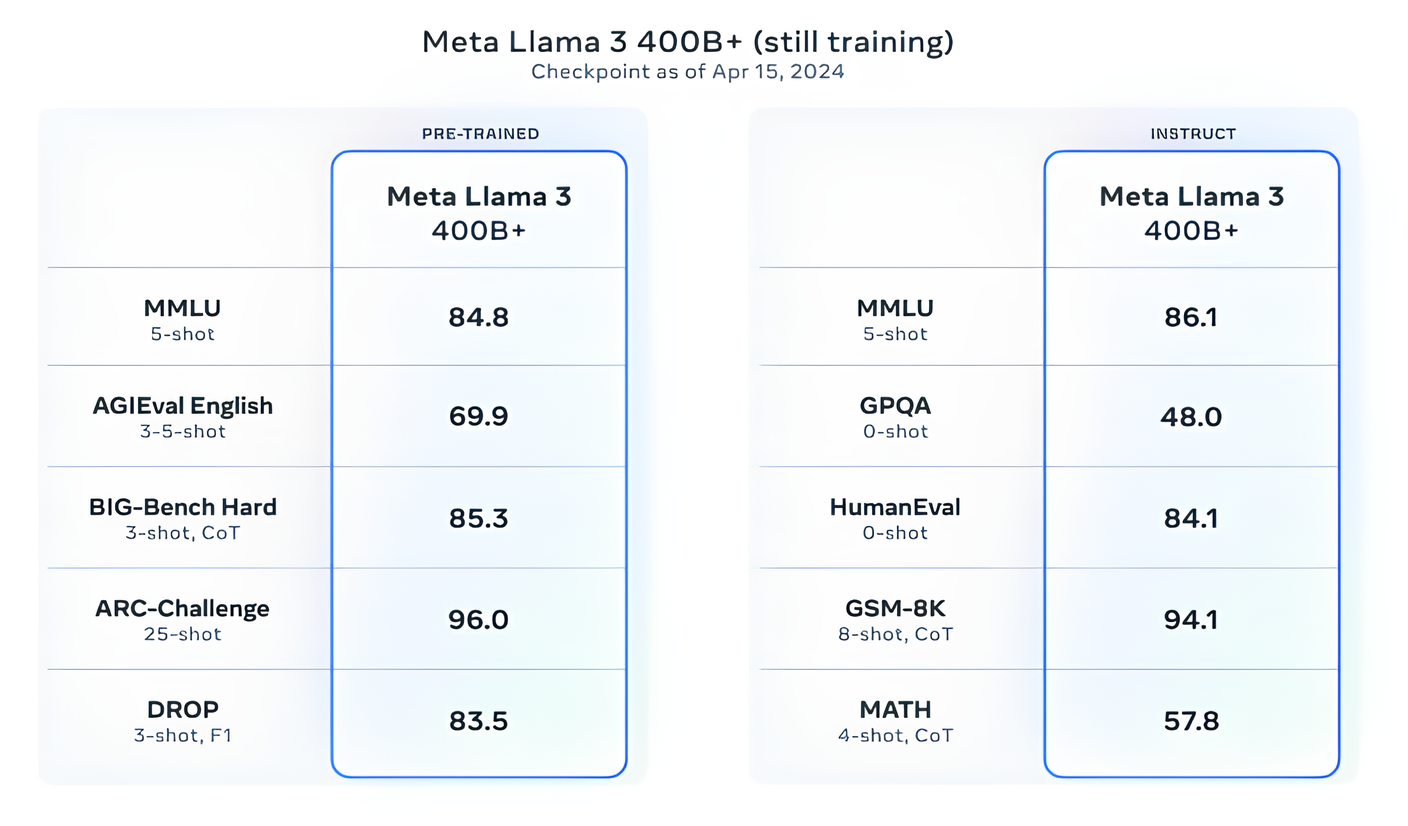
The more I use Llama 3 the more I think that Zuck may have just killed OpenAI and all other large proprietary AI vendors. The gap between latest GPT4 and Llama 70b is virtually non existent. Even if OpenAI releases GPT5 now, 400b Llama 3 is still training and will most likely be…
— Laura Wendel (@Lauramaywendel) April 21, 2024