ByteDance Demoed a Model that Generates Realistic Deepfake Videos
February 20, 2025
IBL News | New York
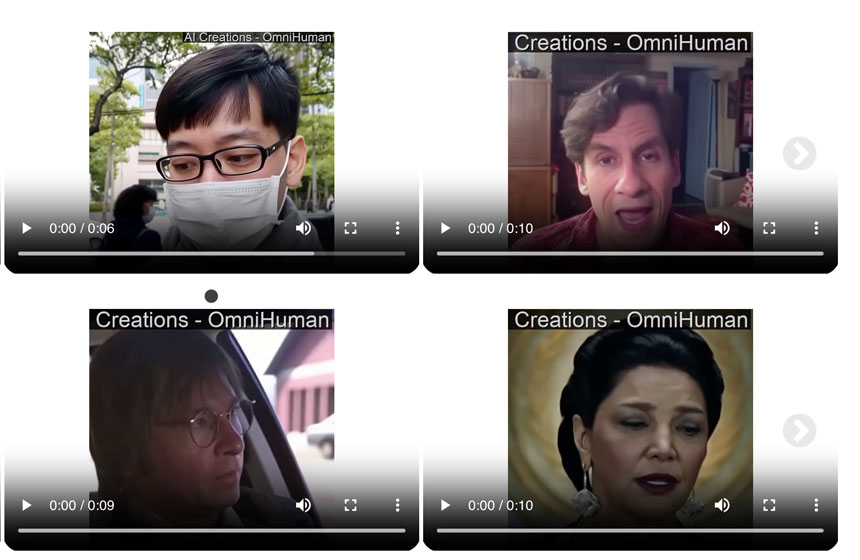
Researchers at ByteDance, owner of TikTok, demoed a model named OmniHuman-1 that generates realistically convincing deepfake videos. However, the Chinese company has yet to release the system.
To prove the quality of OmniHuman-1, the Chinese company released examples of a fictional Taylor Swift performance, a TED Talk that never took place, and a deepfake Einstein lecture, among others [click on the picture to watch videos].
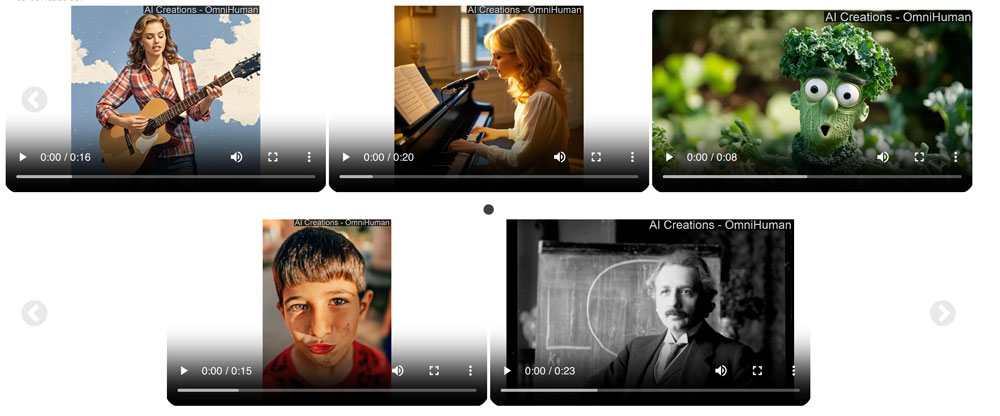
ByteDance researchers said that OmniHuman-1 only needs a single reference image and audio, such as speech or vocals, to generate a clip of arbitrary length.
They said the output video’s aspect ratio and the subject’s “body proportion” — i.e., how much of their body is shown in the fake footage— are adjustable.
Trained on 19,000 hours of video content from undisclosed sources, OmniHuman-1 can edit existing videos—even modifying a person’s movements.