
The ASU+GSV Summit 2026 Shared Institutions' Anxiety in the Age of AI
"OpenAI Is Deploying a Technology that Manipulates Users at No Cost," Writes a Former Researcher in the NYT
"2026 will Be the Year of Agents,” Said the Developer Who Created Open Claw
DeepSeek Issued Its Open Source Model V4 Preview, with a Cost-Effective 1M Context Length
Google Announces Its Enterprise Agent Platform and Unveils Powerful New AI Chips
TOP STORIES

Criminal Group ShinyHunters Breached Instructure's Canvas LMS Again
Instructure, the Owner of Canvas LMS, Acknowledged It Lost 3.6 Terabytes of Critical Data After a Cyberattack

Microsoft, Meta, Oracle Continue Scaling Back Their Workforces In The Age of AI

NVIDIA Continues to Improve Its Claw Open Models for Enterprise

China Has Erased the AI performance Gap With the U.S., Said the Stanford HAI Report

Chegg, Having Lost Most of Its Value, Faces a Survival Struggle
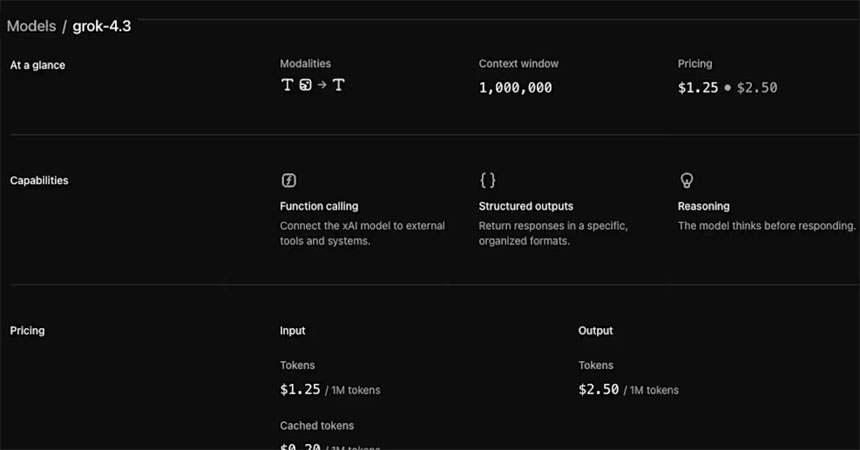
xAI Shipped Its Latest Model, Grok-4.3, with 1M Token Context Window and Low Price API

Owned AI Infrastructure and Data Sovereignty Emerge as Dominant Themes Across Industries

Practitioners at the ODSC Event Examined Why AI Enterprise Projects Failed and Analyzed Tectonic Shifts
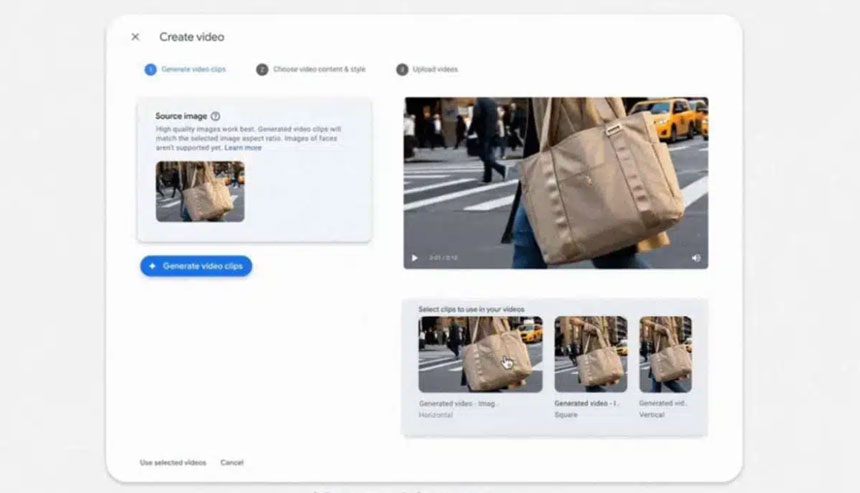
Google Made its Veo Video Model Available for Advertisers
AI LITERACY
ibl.ai


U.S. & World
Tensions between the United States and Iran are escalating as President Trump has deemed Iran's latest offer to end the war as 'totally...
Videos

Hantavirus-hit cruise ship evacuated

Boat explosion in Miami Beach leaves more than a dozen people injured

Adm. McRaven: ‘Of course the ceasefire has been violated’ despite Trump claims
New strikes raise fears Israel-Lebanon ceasefire is collapsing

Passenger recalls moment plane struck person on runway
Technology
River Valley School District in Pennsylvania is the first to implement the Yourway Learning $1 million AI grant, signifying a growing trend in...



Universities
University Budget Cuts and Restructuring
Several universities are implementing cost-cutting measures due to financial pressures. Southern...
Campus Protests and Academic Freedom
Universities are grappling with controversies related to free speech and political activism. A...
Cybersecurity and Technology Disruptions in Education
Educational institutions are increasingly vulnerable to cyberattacks, resulting in significant...